Licence To Page - What I learned from Pagerduty Connect: London

I've just come back from PagerDuty's London conference, and surprisingly I learned a lot. I say I'm suprised and that's because I've never used PagerDuty or any other incident response software.
For the uninitiated, PagerDuty is a service that specialises in "incident response" - the technical term for "poo hitting the fan" - basically providing automated alerts to the right person when something goes wrong. Where I work, incidents are rare (thankfully) and as such, handled in a bespoke manner which definitely would not scale well. Incidents that happen far outside of standard working hours are not monitored. With this in mind, I wanted to learn how we could make the most of other company's teachings to improve our services in this regard. We were very lucky to hear from a number of great speakers on topics like handling risk in high pressure environments, incidient management at a large scale, and building incident management into digital transformation.
Georgina Owens, Director of IT at DAZN (A digital-first sports broadcaster) led a really captivating talk, showing us how insane their setup is and how they set up incident management. DAZN broadcast sports in multiple regions in a range of timezones which means if there's an issue at any time of day or night, enough people will notice. When it comes to sport, paying fans can get very upset if there's any interruptions, meaning DAZN in particular needed to build a good experience.
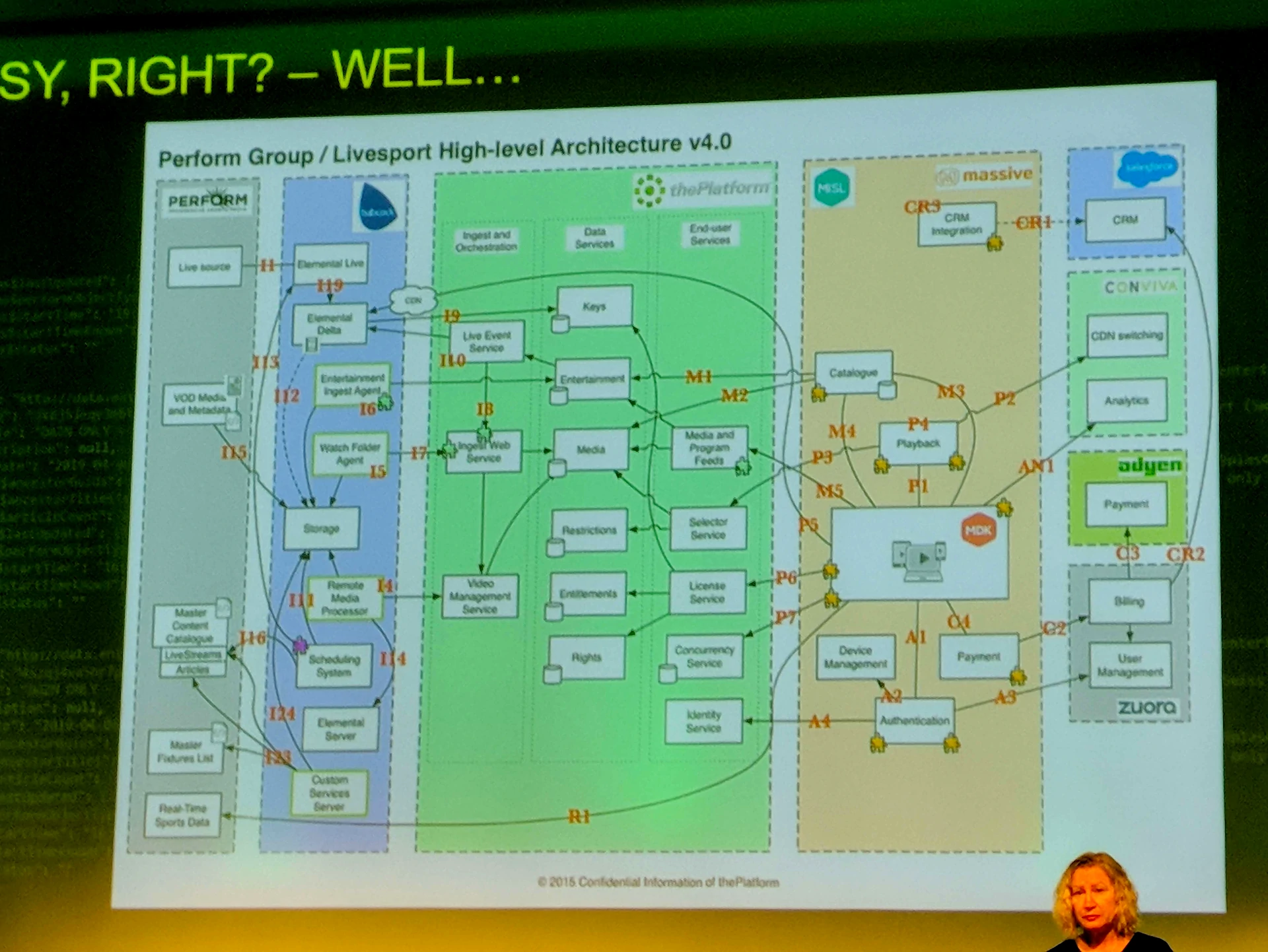
DAZN use Terraform to manage their Pagerduty configuration, something I still don't really understand, but apparently it provides them with more flexibility. DAZN worked with PagerDuty to implement what is known as the "HybridOps" model. Essentially, it entails proactively monitoring services (that have been broken down from a monolitic codebase into separate instances) and using these signals to orchestrate quick responses to issues as they arise. Primarily that means being able to tell a bunch of different systems (engineers over slack, a Jira ticket, or perhaps some system of record for auditing) that something's happening.
Georgina also talked about all the possible points of disruption and how DAZN deal with them - from AWS instance resiliance to CDN coverage to handling audience spikes in advance for big events. It's truly amazing seeing the efforts when as a customer you don't even think about how well the service is performing (until it doesn't.)
Similarly, Chris Evans, co-founder of Monzo, gave their perspective - that of a modern bank. Monzo doesn't have any branches and its customers depend on it being reliable for their livelihoods, so uptime is very important to them. Chris described the "zero-trust" microservice structure they've built, made up of more than one thousand services(!!!) In total, they are checking over 8,000 different "scrape targets" for their health, all automated through Docker. Chris also showed us Monzo's fully-fleshed-out incident response workflow and how to delegate roles across live incident handling, cleanup and outward reporting roles, as well as the extensive Slack integration they've made (with auto-generated incident channels, role designation and action buttons to boot.)
The advice from Chris?

We met with some lovely people from a number of vendors, including Sumo Logic and New Relic, who kindly sponsored the cracking open bar "networking reception".
It seems like I have a lot more to learn about this industry and its relevance to smaller companies especially, and now I have the motivation.
